今天嘗試自己建立模型,並且用昨天創建好的資料來訓練,首先引入需要用到的模組:
from torch import nn
import torch
辨識要使用的裝置:
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
print(f"Using {device} device")
建立CNN模型:
class CustomConvNeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.cnn_module = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=(1, 1), padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3, stride=(1, 1), padding=1),
nn.MaxPool2d(2, 2),
nn.ReLU(),
)
self.fc_modeul = nn.Sequential(
nn.Linear(16 * 15 * 15, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, 7)
)
def forward(self, x):
x = self.cnn_module(x)
x = self.flatten(x)
x = self.fc_modeul(x)
return x
cnn_model = CustomConvNeuralNetwork().to(device)
print(cnn_model)
設定超參數:
# 超參數
learning_rate = 1e-3
batch_size = 64
epochs = 10
# 初始化loss function
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(cnn_model.parameters(), lr=learning_rate)
設定訓練和測試的迴圈:
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
try:
y = torch.tensor(y, dtype=torch.long)
# 將資料讀取到GPU中
X, y = X.to(device), y.to(device)
# 運算出結果並計算loss
pred = model(X)
loss = loss_fn(pred, y)
# 反向傳播
loss.backward()
optimizer.step()
optimizer.zero_grad()
except:
print("image error")
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn):
model.eval()
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
# 驗證或測試時記得加入 torch.no_grad() 讓神經網路不要更新
with torch.no_grad():
for X, y in dataloader:
y = torch.tensor(y, dtype=torch.long)
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
接下來就是訓練的流程:
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(train_dataloader, cnn_model, loss_fn, optimizer)
test_loop(test_loader, cnn_model, loss_fn)
print("Done!")
But,寫程式最容易遇到的 But,訓練時報了錯誤,查了一下Google發現是我的 label 格式錯誤,因此做了修改。
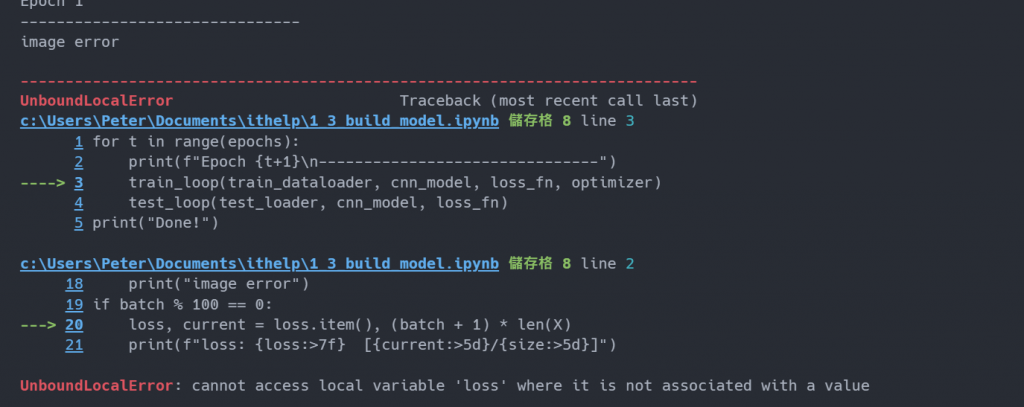
y = torch.tensor(y, dtype=torch.long) 我在資料及新增了這行,順利運行了幾百筆資料又出錯了,這次的錯誤是:
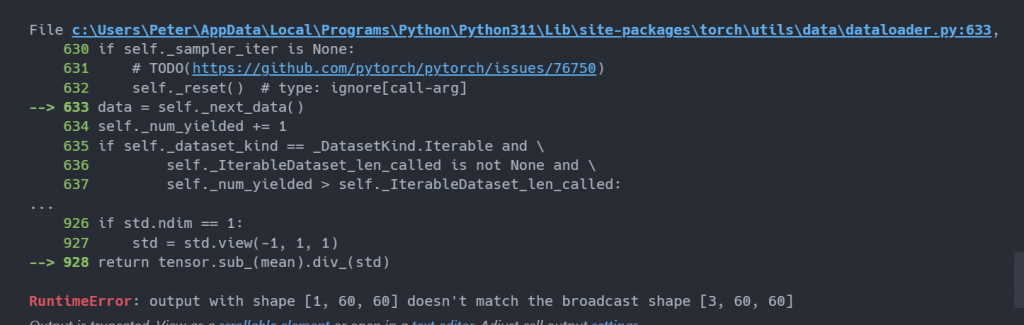
個人猜測有部分資料出問題,可能是圖片損毀之類的,但是今天有點晚了,明天再來嘗試解開這個問題吧~


 iThome鐵人賽
iThome鐵人賽